КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Функция затрат рандомизированного алгоритма
|
|
|
|
П п п
П
П п
E?п=2 E(?„|1фPпаф=^(п -1 + E(?;Х) + E(?;х))±;
1=1 1=1
Глава 2. Сложность в среднем
после очевидного упрощения имеем
E?п = п - 1 + i 2(E(?'П|^) + E(?;Х)).
Займемся вычислением E(?'п|*ф и EСС^Лф, IsS i sS n. Мы имеем разложение
Г\ —= / Ст
где событие G |,' p определено так же, как в предложении 6.1(H), — это событие состоит в том, что относительный порядок элементов перестановки, имеющих значения, меньшие i, совпадает с порядком элементов перестановки р длины i - 1; имеем
E(?;Х)= 2 E(? n | Gn P)P n (G J; p).
рбП-
Когда выполняется Glf, значение £'п(а) равно ^(р). Принимая дополнительно во внимание предложение 6.1(H), имеем
E(?Ж)= £?г-1(р)-Т5Г = E?г-1. Аналогично можно показать, что
здесь надо рассмотреть событие, которое состоит в том, что относительный порядок элементов перестановки, имеющих значения, большие i, совпадает с порядком элементов перестановки p длины n - i. В итоге получаем
| п 1=1 |
E?п = п -1 + - УсE?,! + E?п-о.
Так как £ E?г-1 = £ E?п-г= £ E?fc, то
i =l i =l fc=0
| 2 " |
| n k=0 |
E? n = n - 1 + - У E?fc. (7.1)
§ 7. Пример медленного роста сложности в среднем 55
Таким образом, для Гд5(п) = Е£п мы имеем соотношение
п-1
fQS(n) = n -l + !^? QS(fc), (7.2)
fc=0
fQS(0) = 0. Домножение обеих частей равенства (7.2) на п дает
п-1
n fQS(n) = n (n -l)+2^?QS(fc).
fc=0
При п > 0 имеем для п-1:
л-2
(п - l)fQS(n - 1) = (п - 1)(п - 2) + 2^ fQS(fc).
fc=0
Вычитая почленно последнее равенство из предпоследнего, получаем
n fQS(n) - (п - l)fQS(n - 1) = 2(п - 1) + 2fQS(n - 1),
т. е.
n fQS(n) - (n + l)fQS(n - 1) = 2(п - 1).
Делим последнее равенство на п(п + 1) и переходим к новой неизвестной функции tin) = ^£:
t (n)- t (n -l) = 2 ""* t (0) = 0.
Решением любого уравнения вида t(n) - t{n - 1) = <р(п) при функции <р, определенной для всех п ^ п0, является t(n) = <р(По) + £ <р(к),
|
|
|
к=п0+1
п^п0 (легко доказывается индукцией по п в предположении, что если нижний предел суммирования больше верхнего, то сумма равна нулю). В нашем случае
t (n) = 2V -4^-= 2 У Л-2У ттг—^- (7.3)
Z_i k (k + l) Z_i k +l Z-tk(k + l) у
fc=i fc=i fc=i
Мы имеем V -A-= in n + 0(1); с другой стороны, V —Ц-= 0(1),
поскольку ряд f] * сходится. Таким образом, t (n) = 21n n + 0(l);
fc=i ^ ' отсюда
fQS(n) = (n + l) t (n) = 2 n In п + 0(п). (7.4)
Глава 2. Сложность в среднем
В то же время, сложность в худшем случае T д5(n) есть величина порядка n2 (см. задачу 10).
Число перемещений, требуемое быстрой сортировкой для конкретного массива, не превосходит числа сравнений, домноженного на некоторую небольшую константу, откуда сложность в среднем T ' (n) по числу перемещений элементов допускает оценку T'(n) = = O{n log n).
Сложность в среднем быстрой сортировки как по числу сравнений, так и по числу перемещений элементов допускает оценку O (n log n).
Быстрая сортировка не использует дополнительных массивов, поэтому пространственная сложность по числу одновременно хранимых дополнительных величин, равных каким-то элементам исходного массива, ограничена (небольшой) константой и, как следствие, допускает оценку O (1).
Нелишне заметить, что если быстрая сортировка реализована как рекурсивная процедура, то при ее выполнении будет использован стек отложенных заданий. Рекурсию в данном случае можно организовать так, что в стек будут попадать лишь значения индексов некоторых элементов, но не сами элементы массива. В соответствии с определением алгебраической сложности объем такого стека не влияет на пространственную сложность.
Если выйти за рамки алгебраической сложности, то размер стека отложенных заданий становится важной характеристикой алгоритма. Мы рассмотрим размер этого стека для некоторого типа рекурсивных сортировок, к которому относится не только быстрая сортировка, но и, например, рекурсивный вариант сортировки слияниями. Пусть сортировка организована так, что на первом ее этапе мы, следуя некоторому принципу, выделяем из массива x длины n > 1 две какие-то его непересекающиеся части x ', x ", длина каждой из которых меньше n. На втором этапе эти части сортируются рекурсивно с помощью той же сортировки, и на третьем, заключительном, этапе, исходя из результатов сортировки x ' и x ", массив x представляется, уже без рекурсий, в упорядоченном виде. Если n = О или n = 1, то никаких действий над элементами массива не производится.
|
|
|
Будем использовать для такого рода сортировок рабочее название «бинарные рекурсивные сортировки». Возникающие при выполнении таких сортировок рекурсии реализуются с помощью стека отложенных заданий.
Теорема 7.1. Если некоторая бинарная рекурсивная сортировка такова, что первым из x ', x " сортируется массив, имеющий не пре-
§ 7. Пример медленного роста сложности в среднем
восходящую n длину, то в ходе применения сортировки к массиву x длины n > 1 число отложенных заданий, хранящихся в стеке, никогда не превосходит log2 n.
Доказательство. Проведем индукцию по n. При n = 2 утверждение, очевидно, справедливо. Пусть утверждение доказано для 2, 3,..., n - 1, и пусть массив x, содержащий n элементов, на первом этапе сортировки порождает два массива x ', x ", причем длина n ' первого массива x ' не превосходит -, длина n " второго массива x " не превосходит n - 1. Пусть n " ^ n ' ^ 1. На протяжении сортировки массива x ', помимо отложенных заданий, связанных с сортировкой x ', в стеке будет храниться еще одно задание — сортировать x ". Но в момент, когда сортировка массива x ' завершена, в стеке не останется никаких ее следов; таким образом, по предположению индукции, число отложенных заданий в стеке никогда не превзойдет max{log2 n ' + 1, log2 n"}. В силу того, что n ' ^ § и n " ^ n - 1, мы имеем
max{log2 n ' + 1, log2 n"} ^ log2 n,
что и требовалось. □
Полученная оценка числа отложенных заданий, хранящихся в стеке, является оценкой для сложности в худшем случае и, тем самым, для сложности в среднем тоже.
Принимая во внимание теорему 7.1, мы приходим к варианту быстрой сортировки, представляемому рекурсивной процедурой qsort{k, l), обращение к которой обеспечивает сортировку части xk xk + ъ..., xl исходного массива xг, x2, ■ ■ ■, xn; при k ^ l никаких действий не производится. Сам массив xъx2, ■■■,xn является глобальным по отношению к процедуре:
|
|
|
if k<l then
xk выбирается в качестве разбивающего элемента и выполняется разбиение xk,xk+ъ..., xl; пусть i — индекс, получаемый разбивающим элементом после разбиения; if i-k<l-i then qsort(k,i - 1); qsort(i + 1,l) else qsort (i + 1, l); qsort{k,i-l) fi
fi.
Быстрая сортировка всего массива является результатом выполнения qsort{l,n).
Глава 2. Сложность в среднем
Определение 8.1. Алгоритмы с элементами случайности, реализуемыми обращениями к генераторам случайных чисел, называются рандомизированными.
Рандомизированные алгоритмы можно разделить на вероятностные, или, что то же самое, алгоритмы типа Монте-Карло, и алгоритмы типа Лас-Вегас. Первый тип допускает, что ответ, который дает алгоритм для поставленной задачи с некоторым конкретным входом, может быть неправильным, хотя бы и с малой вероятностью; второй тип — Лас-Вегас—гарантирует правильный ответ, но (как и для алгоритмов типа Монте-Карло) время получения ответа для конкретного входа не определяется, вообще говоря, однозначно этим входом г. Исключая специально оговариваемые редкие случаи, мы будем рассматривать только алгоритмы типа Лас-Вегас, не упоминая этого каждый раз.
Анализ сложности рандомизированного алгоритма сводится к нахождению математических ожиданий некоторых случайных величин. Но ситуация здесь отличается от той, когда множество входов фиксированного размера рассматривается как вероятностное пространство и затраты алгоритма, однозначно определенные для каждого конкретного входа, становятся случайными величинами на этом пространстве (мы шли этим путем в двух предыдущих параграфах). При исследовании рандомизированных алгоритмов вероятностное пространство, на котором рассматриваются случайные величины, состоит из сценариев выполнения алгоритма для фиксированного входа, и каждый сценарий определяется тем, какие случайные числа будут сгенерированы в соответствующие моменты выполнения алгоритма; за каждым таким сценарием закрепляется некоторая вероятность. В нашем контексте генератор случайных чисел можно представлять себе как стандартную функцию random{N) целого положительного аргумента N, результатом выполнения которой является элемент множества {0,1,..., N - 1}, но невозможно предсказать точно, каким именно будет значение этой функции,—любой из элементов указанного множества может появиться с вероятностью 1 /N.
|
|
|
Таким образом, затраты рандомизированного алгоритма при фиксированном входе, вообще говоря, не определяются однозначно, но
1 Эта классификация является достаточно распространенной в специальной литературе по рандомизированным алгоритмам — см., например, книгу [55], — но не единственной. Например, в [26, разд. 9.2] рандомизированные алгоритмы подразделяются иначе, а именно — на алгоритмы типа Монте-Карло, типа Лас-Вегас и шервудские. Мы не будем останавливаться на этом.
§ 8. Функция затрат рандомизированного алгоритма
зависят от сценария вычисления. При фиксированном входе мы можем рассмотреть множество всех сценариев и, приписав адекватным образом каждому из сценариев некоторую вероятность, ввести на полученном вероятностном пространстве случайную величину, значение которой для данного сценария равно соответствующим вычислительным затратам. Значение функции затрат на данном входе можно положить равным математическому ожиданию этой случайной величины (усредненным затратам для данного входа). А после того как определена функция затрат и принято соглашение о том, что такое размер входа, мы можем, как обычно, рассматривать сложность алгоритма— в худшем случае или же в среднем (последнее возможно, если только множество входов каждого фиксированного размера является вероятностным пространством).
Мы не будем здесь сколь-либо глубоко входить в общие проблемы теории сложности рандомизированных алгоритмов, а ограничимся рассмотрением примеров, в которых вероятностное пространство сценариев является одним и тем же для каждого из входов данного размера (в общем случае это не так).
Пример 8.1. Вновь обратимся к быстрой сортировке. В § 7 нами установлено, что быстрая сортировка имеет сравнительно низкую сложность в среднем в предположении, что для каждого п > О все относительные порядки элементов входных массивов длины п имеют
одинаковую вероятность —. Но в некоторых практических задачах это предположение может оказаться безосновательным в силу того, что все входные массивы изначально оказываются, например, «почти упорядоченными». Число сравнений, затрачиваемых быстрой сортировкой на каждом таком «почти упорядоченном» массиве, будет близко к п2, что сведет на нет достоинства быстрой сортировки.
Однако если разбивающий элемент выбирать случайно, то при каждом фиксированном входе размера п усредненные затраты будут иметь порядок n log п, что и будет показано ниже. Итак, под рандомизированной быстрой сортировкой мы будем понимать быструю сортировку со случайным выбором индекса разбивающего элемента; если надо выбрать случайное значение т из fc,fc + l,...,?, то мы полагаем т:= k + randomQ. - к + 1). В том алгоритме, который записан в виде процедуры в конце § 7, вместо
хк выбирается в качестве разбивающего элемента и выполняется разбиение хк,хк+ъ...,х1; пусть i— индекс, получаемый разбивающим элементом после разбиения;
Глава 2. Сложность в среднем
можно написать
m:=fc + random (Z-fc + 1);
xm выбирается в качестве разбивающего элемента и выполняется разбиение хк,хк+ 1,...,х;; пусть i — индекс, получаемый разбивающим элементом после разбиения;
это даст рандомизированный вариант быстрой сортировки.
Пусть дан массив х 1, х2,...,хп попарно различных чисел. Пусть мы выбираем элемент т из множества {1,2,...,п} и вероятность выбора
каждого из элементов есть -. Тогда место хт в массиве х 1, х2,...,хп после сортировки этого массива может оказаться любым с одной и той же вероятностью -. В самом деле, пусть К^пи пусть l(i) та-ково, что Х ( ) занимает после сортировки массива место с номером i. Это Z(i) определяется единственным образом. Поэтому вероятность попадания хт после сортировки массива на i -е место равна вероятности того, что m = Z(i). Последняя вероятность, очевидно, равна -.
п
Следовательно, приписывание одинаковой вероятности каждому возможному выбору индекса разбивающего элемента ведет к тому, что вероятность каждого из событий «после этапа разбиения элемент, выступавший в качестве разбивающего, занимает в массиве i -е место»,
i = 1, 2,..., п, равна -. п
Это обстоятельство позволяет переформулировать задачу анализа сложности рандомизированной быстрой сортировки, например, следующим образом. Имеется полоска бумаги шириной в одну клетку и длиной в п клеток, n ^ 0, которую надо разрезать на отдельные клетки. Разрезы имеет право производить некий разрезальщик, которому надо платить за работу. При п = 0 или п = 1 разрезальщик ничего не делает и ничего не получает. В случае п > 1 он выбирает случайным образом (тянет из шапки билет с номером) значение i из множества {1, 2,...,п} и затем вырезает из полоски i -ю клетку (рис. 8), получая за этот этап работы вознаграждение вп-1 рубль. Кроме вырезанной клетки возникают две полоски, длина каждой из
| m | |||
Рис. 8. Этап разрезания полоски.
§ 8. Функция затрат рандомизированного алгоритма
которых не превышает n - 1, при этом не исключается равенство нулю одной из длин. С каждой из двух полосок разрезальщик проделывает ту же операцию, получая вознаграждение в соответствии с тем же принципом оплаты. Каково математическое ожидание размера вознаграждения, получаемого разрезальщиком за всю работу? Здесь при фиксированном n множество всех возможных сценариев (будем называть их n -сценариями) — это фактически множество
|
|
|
|
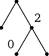
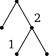
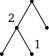
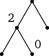
Рис. 9. Сценарии разрезания полоски из трех клеток (3-сценарии).
 некоторых двоичных деревьев; на рис. 9 показано одно из возможных представлений множества всех 3-сценариев. В каждой вершине дерева записывается число клеток в полоске. При произвольном n ^ О понятие п-сценария определяется рекурсивно: О-сценарий и 1-сце-нарий—это одна вершина, которой приписано число 0 или соответственно 1; пусть п > 1,
некоторых двоичных деревьев; на рис. 9 показано одно из возможных представлений множества всех 3-сценариев. В каждой вершине дерева записывается число клеток в полоске. При произвольном n ^ О понятие п-сценария определяется рекурсивно: О-сценарий и 1-сце-нарий—это одна вершина, которой приписано число 0 или соответственно 1; пусть п > 1,
тогда любой n -сценарий s получается выбо- i - 1 / \ n - i
| s' |
| с" |
| Рис. 10. Структура п-сценария. |
ром некоторого числа i, 1 ^ i ^ п, некоторого (i - 1)-сценария s ' и некоторого (п - О-сцена-рия s": из корня п исходят ребра к вершинам i -1 и n-i, к которым подклеиваются корни
сценариев s ' и s " (рис. 10). Каждому п-сцена-
рию s естественным образом приписывается
вероятность P„(s) (здесь индекс п указывает
на то, что вероятность соотнесена с некоторым n -сценарием): если
п = 0 или п = 1, то сценарии имеют вероятность 1, а при п > 1
P n (s) = -P i _ 1(s /) P„ - i (s /0-
(8.1)
Например, третий из 3-сценариев, изображенных на рис. 9, имеет вероятность ^, каждый из остальных—вероятность -т.
Формула (8.1) отражает идею алгоритма, а именно что после определения i выбор (i - 1)-сценария s ' и выбор (п - О-сценария s " независимы друг от друга. Эта формула превращает множество всех п-сце-нариев при фиксированном п в вероятностное пространство S „. Поль-
Глава 2. Сложность в среднем
зуясь индукцией по п, проверим, например, что ^ P n (s) = l: при п = 0 и п = 1 это очевидно, при п > 1 имеем
| s e S „ i = l s 'e S -j s "e S |
| ■i-1 *n-i Yj((Yj Pi-^s'A J] Pn-its"A i = l s 'e S j-j s"<ESn - i |
- P --msm P- i LSJ=- 1-1 = 1.
i =l
Плата за разрезание полоски длины п на отдельные клетки полностью определяется использованным n -сценарием, это задает случайную величину Хп на Sn, и нас интересует математическое ожидание этой величины. Для сценария s, представленного на рис. 10, мы назовем s' и s" левым и правым подсценариями. При п > 1 определим на Sn дополнительно к j n еще две случайные величины %'п и %'^, положив ^(s) = Xi-i(.s') и x'nte) = Xn-i(s"\ где s ' и s " суть левый и правый под сценарии сценария s. Имеем при п > 1
j n (s) = n -l + ^(s)+^'(s). Пусть п > 1. Введем разложение
s n =s^ + s;; +...+s;;, (8.2)
где S ^—это событие «левый подсценарий данного n -сценария является (i - 1)-сценарием (и соответственно правый подсценарий является (n -0-сценарием)», i = l,2,..., n. Очевидно,
Pn(S1n) = Pn(S2n) =... = Pn(Snn) = ±,
поэтому по формуле полного математического ожидания получаем
Л/1 ^_| ««' П'п
1=1
|
|
|
|
|
Дата добавления: 2014-01-11; Просмотров: 313; Нарушение авторских прав?; Мы поможем в написании вашей работы!