КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Группировка статистических данных 2 страница
|
|
|
|
Изучение структуры социально-экономического явления предполагает анализ не только его составных частей, но и соотношений между ними и изменений в этих соотношениях с течением времени.
Основное требование к формируемым группам при образовании структурной группировки заключается в недопущении выделения «пустых» и малочисленных интервалов. При этом допускается, что первая и последняя группы могут содержать незначительное число наблюдений. Если же такие «провалы» встречаются в срединных интервалах, чаще всего это говорит о том, что произошло смешение разных типов явления и исходная совокупность качественно неоднородна.
Структурная группировка позволяет делать выводы о том, какие значения в исследуемой совокупности встречаются чаще всего, какие – реже всего; каков характер изменения структуры совокупности в целом (равномерный или неравномерный).
Структурная группировка представлена в табл. 2.7. Данные группировки показывают, что в 2005 году более 49% населения имело среднедушевой доход ниже 6000 руб. в месяц, а оставшиеся чуть более 50% практически равномерно распределялись по четырем доходным группам от 6000 до 20000 руб. в месяц. Следующие три года демонстрируют некоторое перераспределение долей населения из малообеспеченных групп в пользу «среднего класса» и появление групп более высоких доходов. Однако, окончательный вывод по этим данным сделать нельзя, так как величина среднедушевого денежного дохода здесь представлена в номинальном выражении, т.е. не скорректирована на индекс потребительских цен. Таким образом, для анализа необходимо сопоставить эти данные с реальными доходами населения.
Таблица 2.7
Распределение населения по величине среднедушевого денежного дохода (в процентах) 1
| Все население в том числе со среднедушевыми денежными доходами, руб. в месяц: | ||||
| до 4000,0 | 28,9 | 20,5 | 14,3 | 9,8 |
| 4000,1–6000,0 | 20,3 | 17,7 | 14,8 | 12,0 |
| 6000,1–8000,0 | 14,9 | 14,7 | 13,6 | 12,1 |
| 8000,1–10000,0 | 10,3 | 11,2 | 11,3 | 10,9 |
| 10000,1–15000,0 | 13,9 | 17,1 | 19,1 | 20,1 |
| 15000,1–20000,0 | 11,7 | 8,4 | 10,6 | 12,4 |
| 20000,1–30000,0 | ... | 10,4 | 9,6 | 12,4 |
| свыше 30000,0 | ... | ... | 6,7 | 10,3 |
1) по материалам статистического сборника «Российский статистический ежегодник. 2009»
Аналитическая группировка – это группировка, позволяющая выявить наличие взаимосвязи между различными признаками изучаемого явления и направление этой связи.
Процесс построения аналитической группировки предполагает разделение всех признаков изучаемой совокупности на две группы: факторные, которые влияют на остальные признаки, и результативные, которые изменяются под этим влиянием.
В отличие от других статистических методов анализа взаимосвязи к аналитическим группировкам предъявляется только одно требование – качественная однородность совокупности.
В зависимости от глубины исследования взаимосвязей могут быть построены собственно аналитическая группировка, комбинационная группировка и многомерная группировка.
Построение собственно аналитической группировки заключается в разбиении качественно однородной совокупности на группы по факторному признаку и подсчетом соответственно этим группам среднего значения одного или нескольких результативных признаков с целью выявления между ними взаимосвязи и определения ее направления. При группировании факторного признака стараются сформировать равные или равнонаполненные интервалы.
Систематический рост или снижение среднего значения результативного признака в результате возрастания значений факторного подтверждает наличие между ними прямой или обратной связи соответственно. Бессистемное изменение среднего значения результирующего признака свидетельствует об отсутствии связи с данным фактором.
Комбинационная группировка позволяет более детально оценить зависимость между признаками и направление этой связи. Построение комбинационной группировки для описания связи двух признаков заключается в последовательном разделении групп факторного признака на подгруппы результативного. Желательно, чтобы интервалы формируемых групп были равными или равнонаполненными.
Для оценки наличия и направления связи анализируются максимальные по столбцам или по строкам частоты. Если они располагаются вдоль диагонали, идущей от левого верхнего угла к правому нижнему, то связь между признаками прямая и близкая к линейной. Если максимальные частоты находятся на противоположной диагонали (от правого верхнего угла к левому нижнему), то связь обратная и близкая к линейной. Если же расположение максимальных частот хаотично, связи между признаками нет.
Многомерные группировки позволяют оценить разнонаправленные взаимосвязи большого числа признаков.
Группировки, построенные для разных субъектов за один период времени или для одного субъекта в динамике, позволяют провести анализ изменения характеристик исследуемого явления в различных условиях места и времени соответственно. При этом для целей сравнения группировки должны быть приведены к сопоставимому виду. Эта задача решается с помощью метода вторичной группировки. При этом данный метод снимает проблему сопоставимости лишь в части различий в числе групп и величине интервалов и не касается вопроса сопоставимости исходных данных и процедуры наблюдения.
В отличие от первичной группировки, формирующейся на основе первичных данных, материалом для вторичной служит ранее осуществленная группировка.
Таким образом, вторичная группировка – это процесс перегруппирования уже имеющейся группировки, т.е. создание на ее основе новых групп.
Технически вторичная группировка может быть осуществлена одним из двух способов: объединением первоначальных интервалов или долевой перегруппировкой.
Объединение первоначальных интервалов используется при переходе от более мелких к крупным интервалам, если при этом новые границы совпадают со старыми.
Долевая перегруппировка используется, если для отнесения к той или иной группе в новых границах необходимо определить, какая часть единиц совокупности перейдет из старых групп в новые. Технически долевая перегруппировка заключается в закреплении за каждой группой определенной доли единиц совокупности и распределении этой доли по новым границам при допущении о том, что распределение единиц совокупности внутри каждой группы равномерное.
Статистические таблицы. Их виды и принципы построения
На втором этапе сведения данных переходят к подсчету итогов по группам и совокупности в целом. Предварительно результаты построения группировок оформляются табличным способом.
Статистическая таблица – это таблица, содержащая сводные числовые характеристики изучаемой совокупности по одному или нескольким логически взаимосвязанным признакам.
Подлежащее статистической таблицы – это характеризующийся цифрами объект изучения. Им могут быть единицы совокупности, группы единиц или совокупность в целом. Например, фирмы, регионы, временные периоды и др. Обычно подлежащее таблицы располагается слева, в наименовании строк.
Сказуемое статистической таблицы – это система показателей, являющаяся результатом сводки и характеризующая объект изучения. Обычно сказуемое представлено верхними заголовками, т.е. наименованиями граф, которые располагаются слева направо в логической последовательности.
Общий заголовок – это основное содержание таблицы, представленное в сжатой и ясной форме, с указанием места и времени, к которым относятся составляющие ее сведения.
Основа статистической таблицы изображена на рис. 2.1.
Название таблицы* (общий заголовок)
| Наименование подлежащего | Наименование сказуемого | ||||||
| Верхние заголовки | |||||||
| А | Б | В | … | ||||
| Боковые заголовки | |||||||
| Итоговая строка | Итоговая графа | ||||||
*Примечания к таблице
Рис. 2.1. Основа статистической таблицы
В зависимости от характера подлежащего, различают простые, групповые и комбинационные статистические таблицы.
Подлежащее простой таблицы представляет собой простой перечень объектов, территорий, хронологических дат, т.е. не предусматривает группировки единиц наблюдения. Подлежащее групповой таблицы содержит группировку единиц совокупности по одному количественному или качественному признаку. Подлежащее комбинационной таблицы содержит последовательную группировку единиц совокупности одновременно по нескольким признакам, т.е. комбинационную группировку.
В зависимости от глубины разработки сказуемого, различают простые и сложные статистические таблицы. При простой разработке сказуемого формирующий его показатель не подразделяется на подгруппы. Сложная разработка сказуемого, напротив, предполагает такое деление, что позволяет охарактеризовать каждую группу или единицу объекта разной комбинацией признаков.
При оформлении статистической таблицы необходимо придерживаться следующих правил:
1. компактность и наглядность таблицы; отсутствие избыточных, второстепенных данных; представленные данные должны непосредственно отражать изучаемое явление;
2. краткость формулировок всех заголовков таблицы;
3. указание единиц измерения всех показателей: в заголовке, если они одинаковы, и в наименованиях строк и граф, если разные; использование общепринятых сокращений: чел., руб. и т.д.;
4. формирование объединяющих заголовков при наличии в наименованиях подлежащего или сказуемого общих терминов;
5. расположение взаимосвязанных данных в соседних графах;
6. логичность в последовательности расположения элементов подлежащего и сказуемого (от частного к общему, от абсолютных величин к средним и относительным и т.д.);
7. одинаковая степень точности в округлении числовых данных;
8. правильное отображение отсутствия данных: прочерк - при отсутствии явления, «нет сведений» или «…» - при отсутствии информации о явлении; в не подлежащих заполнению ячейках ставится «Х»; если значение составляет величину меньше принятой точности, ставится (0,0) или (0,00) и т.д.
9. необходимость итоговых строк/граф в групповых и комбинационных таблицах; если они завершают таблицу, используют слова «Итого» или «Всего», если открывают – дополняются словами «в том числе» с последующей конкретизацией.
После чтения таблицы, т.е. ознакомления с содержанием, производится ее анализ, который состоит в выявлении особенностей исследуемого явления и основных тенденций его развития. Процедура анализа при этом проходит обычно от общих итогов к частным с выявлением наиболее характерных черт, сопоставлением частей и формулированием общих выводов из таблицы.
Ряды распределения: дискретные, интервальные. Построение интервальных рядов. Частоты, частости, плотности распределения. Кумулятивные ряды
Составной частью операций по обработке полученных при группировании данных является построение ряда распределения.
Ряд распределения – это упорядоченное распределение единиц совокупности по группам по какому-либо варьирующему признаку.
Ряд распределения строится, исходя из принципов статистической группировки. Технически это реализуется с помощью простой группировки интересующего признака, в которой каждому значению или интервалу поставлено в соответствие количество единиц совокупности, удовлетворяющих этому значению/интервалу.
Таким образом, ряд распределения состоит из двух структурных элементов: вариант и частот и/или частостей.
Варианта, 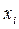 – это конкретное значение варьирующего признака в ряду.
– это конкретное значение варьирующего признака в ряду.
Частота, 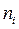 – численность отдельных вариант или каждой группы вариант, показывающая, как часто встречаются эти значения в ряду распределения. Сумма частот по всем группам равна объему совокупности, т.е.:
– численность отдельных вариант или каждой группы вариант, показывающая, как часто встречаются эти значения в ряду распределения. Сумма частот по всем группам равна объему совокупности, т.е.:
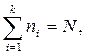
где - число наблюдений в i – ой группе;
k – число групп;
N – число единиц совокупности.
Частость, 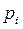 – это частота, выраженная в долях единицы или в процентах к итогу. Сумма частостей по всем группам равна 1 или 100% соответственно, т.е.:
– это частота, выраженная в долях единицы или в процентах к итогу. Сумма частостей по всем группам равна 1 или 100% соответственно, т.е.:
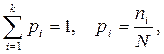
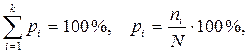
где 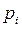 - частость в i – ой группе, выраженная в долях единицы или в процентах к итогу;
- частость в i – ой группе, выраженная в долях единицы или в процентах к итогу;
- частота в i – ой группе.
В зависимости от признака, лежащего в основании, различают атрибутивные и вариационные ряды распределения. Так как ряд распределения является, по сути, группировкой, то виды рядов распределения полностью соответствуют описанным выше возможным градациям группировок.
Атрибутивный ряд распределения – это ряд, построенный по качественному признаку.
Вариационный ряд распределения – это ряд, построенный по количественному признаку. Характер вариации последнего может быть дискретным или непрерывным. Соответственно, различают дискретные и интервальные вариационные ряды. Как и при группировании, если число возможных градаций дискретного признака велико, для него строится интервальный вариационный ряд.
Например, если выбрать один интересующий год, то табл. 2.6 легко трансформируется в атрибутивный ряд распределения занятых по формам собственности в выбранном году, а табл. 2.7 - в интервальный ряд распределения населения по среднедушевому доходу.
Изучение рядов распределения позволяет выявить наличие и определить характер закономерности в изменении частот с изменением значений варьирующего признака, т.е. проследить закономерности распределения. Закономерности распределения призваны отразить основные свойства изучаемого явления.
При этом актуальным становится требование однородности, предъявляемое к структурным группировкам, в противном случае произойдет смешение распределений, отражающих разные явления. Косвенным подтверждением этого может служить описанный выше вариант появления при группировании малочисленных срединных интервалов.
Выявление подлинной закономерности может затруднить и неверная интерпретация результатов построения интервального вариационного ряда, который может быть равноинтервальным и неравноинтервальным.
При построении неравноинтервального вариационного ряда распределения сравнение частот по группам неправомерно, так как изменение границ интервалов может привести к совершенно противоположным выводам. Следовательно, для корректного отражения распределения признака необходимо избавиться от влияния величины интервала, что осуществляется путем перехода от частот/частостей к плотности распределения.
Абсолютная плотность распределения, 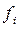 - это частота, рассчитанная на единицу интервала, т.е.:
- это частота, рассчитанная на единицу интервала, т.е.:
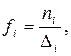
где 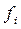 - абсолютная плотность распределения в i – ой группе;
- абсолютная плотность распределения в i – ой группе;
- частота в i – ой группе;
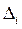 - величина i – го интервала.
- величина i – го интервала.
Относительная плотность распределения, 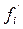 - это частость, рассчитанная на единицу интервала, т.е.:
- это частость, рассчитанная на единицу интервала, т.е.:
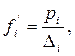
где 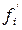 - относительная плотность распределения в i – ой группе;
- относительная плотность распределения в i – ой группе;
- частотость в i – ой группе;
- величина i – го интервала.
Для возможности сопоставления распределений дискретных и интервальных величин используется универсальный подход, основанный на расчете накопленных частот/частостей. Эти величины определяются путем последовательного суммирования частот/частостей по группам с подсчетом итогов к концу каждой группы.
Накопленная частота/частость, 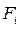 /
/ 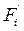 - это число/доля единиц совокупности со значением признака не больше заданного, т.е.:
- это число/доля единиц совокупности со значением признака не больше заданного, т.е.:
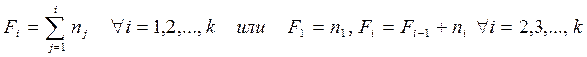
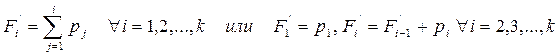
где 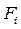 /
/ 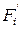 - накопленная частота/частость к концу i – ой группы;
- накопленная частота/частость к концу i – ой группы;
/ - частота/частость в i – ой группе.
Эти величины, будучи рассчитаны через частоты/частости, не могут быть отрицательны (значение «ноль» они принимают к началу первого интервала), а их максимум ограничен объемом совокупности. К концу последней группы этот максимум должен быть достигнут. Кумулятивный характер накопленных частот/частостей подразумевает, что с возрастанием групповых значений их величины могут только увеличиваться. Таким образом:
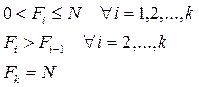
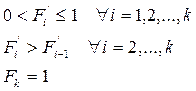
Если в какой-то группе значение накопленной частоты/частости совпадает ее предыдущим значением, значит, рассматриваемая группа не содержит ни одного наблюдения, т.е. является «пустой», что свидетельствует о необходимости перегруппировки.
Обратная процедура – расчет частот/частостей через накопленные частоты/частости – также возможна:
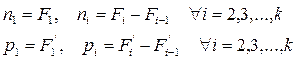
Графическое представление статистических данных
Удобнее всего анализировать ряды распределения с помощью их графического представления. Наряду с таблицами, график – это метод обобщения исходной информации. Графики позволяют более наглядно и доступно для восприятия отразить интересующие характеристики, взаимосвязи, тенденции в исследуемом явлении.
Статистический график – это чертеж, отображающий характеристики той или иной статистической совокупности с помощью геометрических образов или знаков. В статистике используется большое множество графических изображений различающихся и по выбранной основе графика (линейные, плоскостные, объемные), и по способу построения (диаграммы, статистические карты).
Для правильного построения графика необходимо выполнение набора правил: от внешнего оформления (название графика, подписи масштабных шкал, пояснения) до формирования основных элементов графика (графический образ, поле графика, пространственные и масштабные ориентиры).
Применительно к рядам распределения используют следующие графические изображения: полигон, гистограмма, кумулята, огива. Все эти графики строятся в прямоугольной системе координат.
Полигон – графическое изображение дискретного вариационного ряда распределения, дающее представление о характере изменения его частот. Для построения полигона по оси абсцисс в одинаковом масштабе откладываются ранжированные значения варьирующего признака, по оси ординат – частоты или частости.
Полигон представляет собой точки пересечения абсцисс и ординат, которые иногда для наглядности соединяют прямыми, получая ломаную линию. Если варьирующий признак теоретически может принимать значения меньше зарегистрированного минимального и/или больше зарегистрированного максимального, полигон замыкают на оси абсцисс в этих значениях.
В табл. 2.8 представлен дискретный ряд распределения общероссийского жилого фонда по типу квартир. Полигон этого ряда представлен на рис. 2.2.
Таблица 2.8
Распределение жилого фонда по типу квартир в 2008 году1
| Группы квартир по числу комнат | Количество квартир | |
| всего, млн. | в % к итогу | |
| варианты,
| частота,
| частость,
|
| 13,7 | 23,2 | |
| 23,6 | 40,0 | |
| 17,2 | 29,2 | |
| 4 и более | 4,5 | 7,6 |
| ВСЕГО | 59,0 | 100,0 |
1) по материалам статистического сборника «Российский статистический ежегодник. 2009»
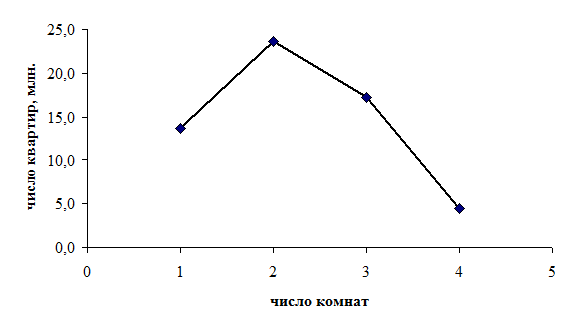
Рис. 2.2. Полигон распределения жилого фонда по типу квартир в 2008 году
Гистограмма (ленточная диаграмма) – графическое изображение интервального вариационного ряда распределения, дающее представление о характере изменения его частот. При построении гистограммы по оси абсцисс откладываются величины интервалов соответствующего признака, по оси ординат – частоты, частости или плотности распределения. Для равноинтервальных рядов могут быть использованы и частоты/частости, и плотности, для неравноинтервальных – только плотности.
Гистограмма представляет собой прямоугольники, ширина которых определяется интервалами на оси абсцисс, а высота – значениями частот, частостей или плотностей на оси ординат.
При построении графиков для дискретных или равноинтервальных рядов распределения выбор между частотами и частостями определяется необходимостью сравнения этих графиков для разных совокупностей (с различным числом наблюдений) в одной системе координат. В случае такой необходимости по оси ординат должны откладываться частости.
В табл. 2.9 представлен интервальный вариационный ряд распределения населения по величине среднедушевых денежных доходов.
Таблица 2.9
Распределение населения по величине среднедушевых денежных доходов в 2007 году1
| Группы населения по среднедушевому доходу, тыс.руб/мес | Численность | Величина интервала, млн.чел | Плотность распределения | ||
| всего, млн.чел | в % к итогу | абсолютная | относительная | ||
| группы вариант,
| частота,
| частость,
|
| плотность частоты,
| плотность частости,
|
| до 2 | 3,7 | 2,6 | 1,8 | 1,3 | |
| 2 – 4 | 16,9 | 11,9 | 8,5 | 6,0 | |
| 4 – 6 | 21,2 | 14,9 | 10,6 | 7,5 | |
| 6 – 8 | 19,3 | 13,6 | 9,7 | 6,8 | |
| 8 – 10 | 16,1 | 11,3 | 8,0 | 5,7 | |
| 10 – 15 | 27,2 | 19,1 | 5,4 | 3,8 | |
| 15 – 25 | 23,5 | 16,5 | 2,3 | 1,7 | |
| свыше 25 | 14,4 | 10,1 | 1,4 | 1,0 | |
| ВСЕГО | 142,2 | 100,0 | - | - | - |
1) по материалам статистического сборника «Социальное положение и уровень жизни населения России. 2008»
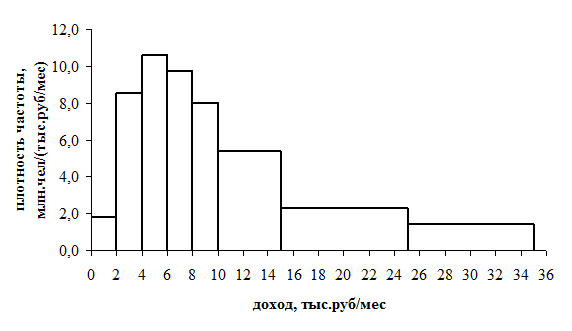
Рис. 2.3. Гистограмма распределения населения по величине среднедушевых денежных доходов в 2007 году
Для правильной оценки распределения данного ряда используется характеристика плотности, т.к. ряд неравноинтервальный. Например, при оценке по частоте/частости создается впечатление, что наиболее «популярным» является интервал от 10 до 15, однако, плотность частоты/частости показывает, что в действительности таким интервалом является диапазон от 4 до 6. Гистограмма этого ряда представлена на рис. 2.3.
Кумулята – графическое изображение кумулятивной кривой, дающее представление о характере изменения накопленных частот/частостей. Для построения кумуляты интервального вариационного ряда по оси абсцисс откладываются величины интервалов, а если ряд дискретный - ранжированные значения признака. По оси ординат в обоих случаях располагаются накопленные частоты или частости. Равенство или неравенство интервалов для графика кумуляты значения не имеет.
Кумулята интервального вариационного ряда представляет собой неубывающую ломаную линию, соединяющую точки пересечения концов интервалов с соответствующими им накопленными частотами. При этом соединение точек прямыми линиями обусловлено предположением о равномерном нарастании ряда накопленных частот внутри интервала. Угловой коэффициент звена кумуляты характеризует плотность распределения в соответствующем интервале: чем круче расположено звено относительно оси абсцисс, тем больше плотность в данном интервале.
В табл. 2.10 представлены значения накопленного ряда для характеристики среднедушевых доходов. По этим данным построена кумулята на рис. 2.4.
Кумулята дискретного вариационного ряда - это неубывающая, ступенчатая кривая: в прямоугольной системе координат отмечают точки, абсцисса которых – значение признака, ордината – накопленная частота/частость. Из точек опускают перпендикуляры на ось абсцисс. Затем из каждой точки откладывают вправо отрезок параллельный оси абсцисс до пересечения со следующим перпендикуляром.
Таблица 2.10
Распределение населения по величине среднедушевых денежных доходов в 2007 году1
|
,
тыс.руб/мес
| Численность | |||
| ,
млн.чел
|
,
в % к итогу
| накопленным итогом, млн.чел. | накопленным итогом, в % к итогу | |
| накопленная частота,
| накопленная частость,
| |||
| до 2 | 3,7 | 2,6 | 3,7 | 2,6 |
| 2 – 4 | 16,9 | 11,9 | 20,6 | 14,5 |
| 4 – 6 | 21,2 | 14,9 | 41,8 | 29,4 |
| 6 – 8 | 19,3 | 13,6 | 61,2 | 43,0 |
| 8 – 10 | 16,1 | 11,3 | 77,2 | 54,3 |
| 10 – 15 | 27,2 | 19,1 | 104,4 | 73,4 |
| 15 – 25 | 23,5 | 16,5 | 127,9 | 89,9 |
| свыше 25 | 14,4 | 10,1 | 142,2 | 100,0 |
| ВСЕГО | 142,2 | 100,0 | - | - |
1) по материалам статистического сборника «Социальное положение и уровень жизни населения России. 2008»
|
|
|
|
|
Дата добавления: 2014-11-29; Просмотров: 1067; Нарушение авторских прав?; Мы поможем в написании вашей работы!