КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Построение функции предпочтений
Работа с системой DSS-UTES начинается с того, что пользователь определяет и вводит в систему показатели, по совокупности которых он хочет оценивать принимаемые решения. Они могут иметь как количественный, так и качественный характер, т.е. часть их может измеряться с помощью чисел, а другая часть с помощью лексических высказываний (хорошо, плохо и т.п.). Затем для каждого из показателей указывается область его возможных значений и величина шага изменения (градация). В результате в системе формируется так называемое критериальное пространство, которое содержит все возможные комбинации значений показателей, выбранных пользователем. Конечно, не все эти комбинации практически реализуемы (например, случай, когда все показатели одновременно приняли наилучшие значения), но это не должно заботить пользователя. Важно лишь, чтобы область возможных значений каждого показателя была представлена с исчерпывающей полнотой.
Приведем в качестве примера задачу оценки кандидатов на замещение некоторой вакантной должности. Примем следующую систему показателей: 1."возраст" - количественный показатель, изменяющийся от 25 до 40 лет с шагом 5 лет; 2."образование" - качественный с тремя градациями: "среднее", "высшее", "ученая степень"; 3."стаж работы по данной специальности" - количественный, изменяющийся от 0 до 20 лет с шагом 5 лет; 4."знание английского языка" - качественный с двумя градациями; "владеет", "не владеет". Эти четыре показателя отражают подход составителя примера к выбору сотрудника. Естественно, что другой человек будет иметь иной подход и введет свою систему показателей, отличающуюся от приведенной, как по существу показателей, так и по их числу. Это подчеркивает тот факт, что система DSS-UTES настраивается на конкретного пользователя уже на начальном этапе (формирование критериального пространства).
Размерность критериального пространства равна числу введенных показателей, а число возможных комбинаций их значений легко подсчитать по формуле N = S(K1)*S(K2)*...*S(Kn), где S(Ki) - число градаций i-го показателя, n - число показателей (в приведенном примере размерность равна 4-м, а число комбинаций значений показателей 120-ти). В системе никаких ограничений на размерность критериального пространства не наложено. Однако, пользователь, формируя его, должен искать компромисс между желаемой полнотой описания результатов принимаемых решений, которая растет с увеличением числа показателей и их градаций, и трудностями сопоставления по предпочтениям всех их комбинаций.
Этап формирования критериального пространства весьма принципиален и играет определяющую роль в процессе принятия решений. Все дальнейшие операции по поиску наилучших решений и ранжированию альтернатив будут производиться в границах этого пространства. Выполнение этого этапа вынуждает пользователя четко сформулировать свое понимание задачи и цели, которую он хочет достичь. Диалог с системой помогает ему в этом.
После того как критериальное пространство сформировано, пользователь приступает к построению своей функции предпочтений. При этом предполагается, что, рассматривая значения двух совокупностей показателей, он всегда может сказать, какая из них, с его точки зрения, предпочтительнее, или же они равноценны. Весьма существенно, что эта процедура не требует от него количественных оценок степени предпочтений, что всегда затруднительно, достаточно лишь сопоставления. В системе DSS-UTES такие сопоставления выполняются на плоских (двумерных) сечениях функции предпочтений. Это делается следующим образом.
Из множества введенных им показателей пользователь выбирает любые два (например, 1 и 2), которые условимся называть активными. Желательно, но не обязательно, чтобы они обладали наибольшим числом градаций или же представлялись ему наиболее важными. Оставшиеся N-2 показателя - пассивные.
Активные показатели образуют решетку, содержащую S(1)*S(2) клеток. Каждая клетка отражает определенную комбинацию значений активных показателей. Пользователь должен расставить свои предпочтения на этой решетке. Для этого ему надо раскрасить клетки в различные оттенки одного цвета, который он может выбрать по своему вкусу. В системе по умолчанию принята черно-белая цветовая шкала. Принято также, что клетка, имеющая более светлый оттенок, предпочтительнее, чем та, что темнее. Соответственно клетки одной тональности - равноценны. Перед раскрашиванием плоскости активных критериев пользователь должен назначить значения всех пассивных показателей, при которых он будет производить раскраску. Эти значения он выбирает по своему усмотрению, но выполнение дальнейших процедур упростится, если он каждому пассивному критерию припишет его минимально допустимое значение. По окончании раскрашивания пользователь изменяет значение одного из пассивных показателей и производит раскраску снова. И такая процедура должна повторяться до тех пор, пока не будут определены предпочтения на всех двумерных сечениях, соответствующих всем возможным комбинациям значений пассивных показателей. В результате в базу знаний системы будет записана информация в виде, позволяющем сравнить по предпочтениям пользователя две любые совокупности значений показателей. Для использования этой информации в задачах оптимизации и ранжирования ей необходимо придать числовую форму. Достигается это путем построения функции предпочтений.
При раскраске двумерных сечений для облегчения работы пользователя на экран выводится палитра полутонов, и работа пользователя при назначениях предпочтений сводится к выбору из этой палитры нужного полутона. Эти полутона расположены в порядке возрастания "светлости" и их можно перенумеровать, например, от черного до белого. Тогда для сопоставления совокупностей значений показателей достаточно сравнить номера присвоенных им полутонов. Та, чей номер выше - предпочтительнее.
На рис.1 приведена экранная форма, соответствующая этапу формирования функции предпочтений. Показаны раскрашенное двумерное сечение ФП, перечень пассивных показателей с указаниям "замороженных" значений и палитра полутонов. Все полутона перенумерованы, что облегчает пользователю процесс раскрашивания. Эту же нумерацию можно рассматривать как множество возможных значений функции предпочтения. Соответственно, чем больше полутонов содержит палитра, тем выше разрешающая способность системы по предпочтениям. В частности, для того, чтобы различать по предпочтениям все возможные комбинации значений показателей, их число должно равняться числу полутонов палитры. Но практически требуемое (или используемое) количество полутонов заметно меньше, т.к. существует большое число равных по предпочтениям комбинаций значений показателей. В частности, равными по предпочтениям являются все комбинации, в которых хотя бы один показатель имеет недопустимое значение.
Экранная форма Редактирования предпочтений
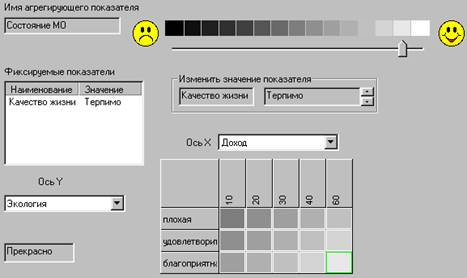
Рис. 1.
Раскрашенная картинка представляет собой как бы вид сверху на сечение ФП. Оно может быть изображено в трехмерном пространстве в виде некоторой ступенчатой поверхности, участки которой тем выше, чем светлее в плане (рис. 2). Такое изображение более наглядно представляет пользователю сделанные им назначения, и после его рассмотрения он может их скорректировать. Для этого в системе предусмотрена возможность обращения к пакету трехмерной графики. В первой версии DSS-UTES использовался пакет BOINGGRAF.
Трехмерное представление сечения
|
|
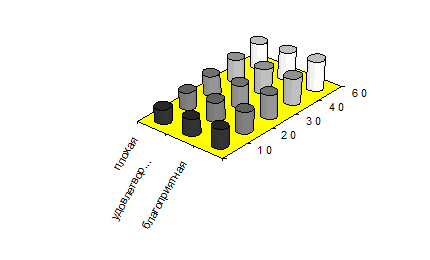
Рис. 2.
Описанная процедура выявления и формализации предпочтений выполняется относительно просто, если число введенных показателей не превышает 5-ти и количество градаций каждого не слишком велико. В дальнейшем ее трудоемкость возрастает настолько резко, что она может стать практически невыполнимой. Это, в первую очередь, связано с тем, что при переходе от одного пассивного показателя к другому и при изменении их "замороженных" значений приходится запоминать предыдущие назначения.
Для снятия этого ограничения в системе DSS-UTES предусмотрен комплекс мер технического и методологического характера. А именно: доопределение функции предпочтений; агрегирование показателей; построение ФП для случая показателей, независимых по предпочтениям.
ДООПРЕДЕЛЕНИЕ. В системе предусмотрены средства, позволяющие устанавливать уровень предпочтений сразу на все двумерное сечение, или на его часть. Например, на всем сечении можно установить "недопустимо", если значение хотя бы одного из показателей находится на этом уровне. Другой пример: если при изменении значения одного из пассивных показателей характер распределения предпочтений на двумерном сечении не меняется, то можно равномерно увеличить или уменьшить уровень предпочтений сразу на всем сечении, и пользователю важно лишь определить величину его подъема или понижения. В этом случае ФП строится как бы по слоям. Процедуры доопределения, хотя и не сокращают размерность критериального пространства, но значительно уменьшают число комбинаций, подлежащих рассмотрению.
АГРЕГИРОВАНИЕ. Если количество показателей, которые пользователь считает необходимым учитывать, настолько велико, что основная процедура построения ФП практически невыполнима, он может прибегнуть к агрегированию. Для этого он должен на основе содержательного анализа разбить все множество показателей на группы, содержащие не более 3-4-х показателей, и построить функции предпочтения для каждой из групп. Таким образом, он в 3-4 раза сократит размерность критериального пространства. Если таких групп окажется не более 5-ти, пользователь может построить результирующую функцию предпочтений, применяя основную процедуру. Если более, то агрегирование надо повторить на группах. При вычислении результирующей ФП надо иметь в виду, что все показатели, характеризующие группы, измеряются в одной и той же шкале, а именно шкале предпочтений. Эта шкала лексическая, и ее градации те же, что и у палитры полутонов. Для облегчения построения ФП и увеличения содержательности процедуры, им следует дать наименования. Это достигается путем присвоения каждому полутону имени, отражающего его место в шкале предпочтений. Эти имена пользователь может придумывать сам или же воспользоваться шкалой основной процедуры назначения предпочтений, прописанной в системе по умолчанию. Следует иметь в виду, что при формировании групп пользователь, исходя из содержания показателей, может часть из них оставить не агрегированными, или, другими словами, иметь группы, содержащие только один показатель. Такие показатели измеряются в первоначальной шкале.
Необходимо, чтобы формирование групп показателей выполнялось либо самим пользователем, либо при его непосредственном участии. Этого требует основной принцип ориентации решений на пользовательское понимание задачи, заложенный в системе.
НЕЗАВИСИМОСТЬ ПО ПРЕДПОЧТЕНИЯМ. Показатели независимы по предпочтениям, если предпочтительность значений любого из них не зависит от того, какие значения приняли другие показатели. В этом случае ФП может быть легко построена для любого числа показателей без обращения к процедурам доопределения или агрегирования. Суть метода сводится к следующему. Рассматриваются последовательно все показатели, и для каждого из них, независимо от других, назначаются, в соответствии с принятыми шкалами, предпочтительности всех возможных значений. В результате этой операции все показатели оказываются измерены в одной и той же лингвистической шкале - шкале предпочтений (полутонов). После чего предпочтения, определенные на показателях, свертываются в результирующую функцию предпочтений пользователя.
Шкалы предпочтений, построенные на отдельных показателях, примечательны тем, что они отражают не столько значения показателей, сколько отношение пользователя к этим значениям. Характерной их особенностью является нелинейность. Назначение предпочтений на показателях принципиально может производиться в рамках основной процедуры построения ФП. Для этого достаточно "заморозить" значение одного из активных показателей, и двумерное сечение станет шкалой предпочтений другого. Однако, для удобства пользователя в системе DSS-UTES эта процедура прописана отдельно.
Свертку показателей (измеренных в шкале предпочтений) в результирующую фикцию предпочтений пользователя можно производить, в силу их независимости, используя один из формальных методов (см. выше). В системе для этой цели принят метод "среднего взвешенного". Он выбран потому, что очень прост и прозрачен для пользователя. В соответствии с ним результирующие предпочтения вычисляются по формуле:
Wаг = k(1)*w(1) + k(2)*w(2) + k(3)*w(3) +... + k(n)*w(n),
где w(i) - значение i-го показателя в шкале предпочтений,
k(i) - коэффициент важности (весовой коэффициент) i-го показателя,
n - количество показателей,
k(1) + k(2)+....+ k(n) = 1.
Коэффициенты важности могут назначаться самим пользователем или экспертами. В последнем случае они непременно должны быть согласованы с пользователем. Если число показателей велико, то выполнение этой процедуры может оказаться слишком сложным. В этом случае для назначения коэффициентов важности может быть использован метод парных сравнений. В DSS-UTES реализован так называемый "аддитивный метод парных сравнений". Суть его состоит в том, что пользователь для всех пар показателей назначает коэффициенты а(i,j), показывающие насколько i-й показатель важнее j-го. При этом должно выполняться условие а(i,j) + а(j,i) = 1. После того как все попарные важности назначены, система, уже в автоматическом режиме, вычисляет искомые коэффициенты а(i). Использование метода парных сравнений облегчает задачу пользователя тем, что ему каждый раз приходиться сравнивать лишь два показателя и не держать в уме все сделанные ранее назначения. При большом числе показателей метод парных сравнений не только проще и нагляднее, но и отнимает меньше времени, нежели непосредственные назначения.
В результате проведения вышеописанных операций в системе формируется функция предпочтений пользователя. Ее значения составляют последовательность чисел, каждое из которых отображает определенную комбинацию значений показателей. Чем предпочтительнее комбинация, тем выше уровень ФП (больше число). Для правильного понимания функции предпочтений и ее роли в системе надо помнить, что она не измеряет предпочтительности комбинаций значений критериев, а только устанавливает их отношения. Иными словами, с помощью ФП можно сказать, какая из двух комбинаций более предпочтительна, но нельзя сказать на сколько, или во сколько раз. Это отличает функцию предпочтений от широко известной функции полезности.
С формальной точки зрения ФП - это неотрицательная, монотонная по предпочтениям скалярная функция n аргументов, где n - число показателей.
|
|
Дата добавления: 2015-05-29; Просмотров: 5363; Нарушение авторских прав?; Мы поможем в написании вашей работы!